存储层优化点
列存
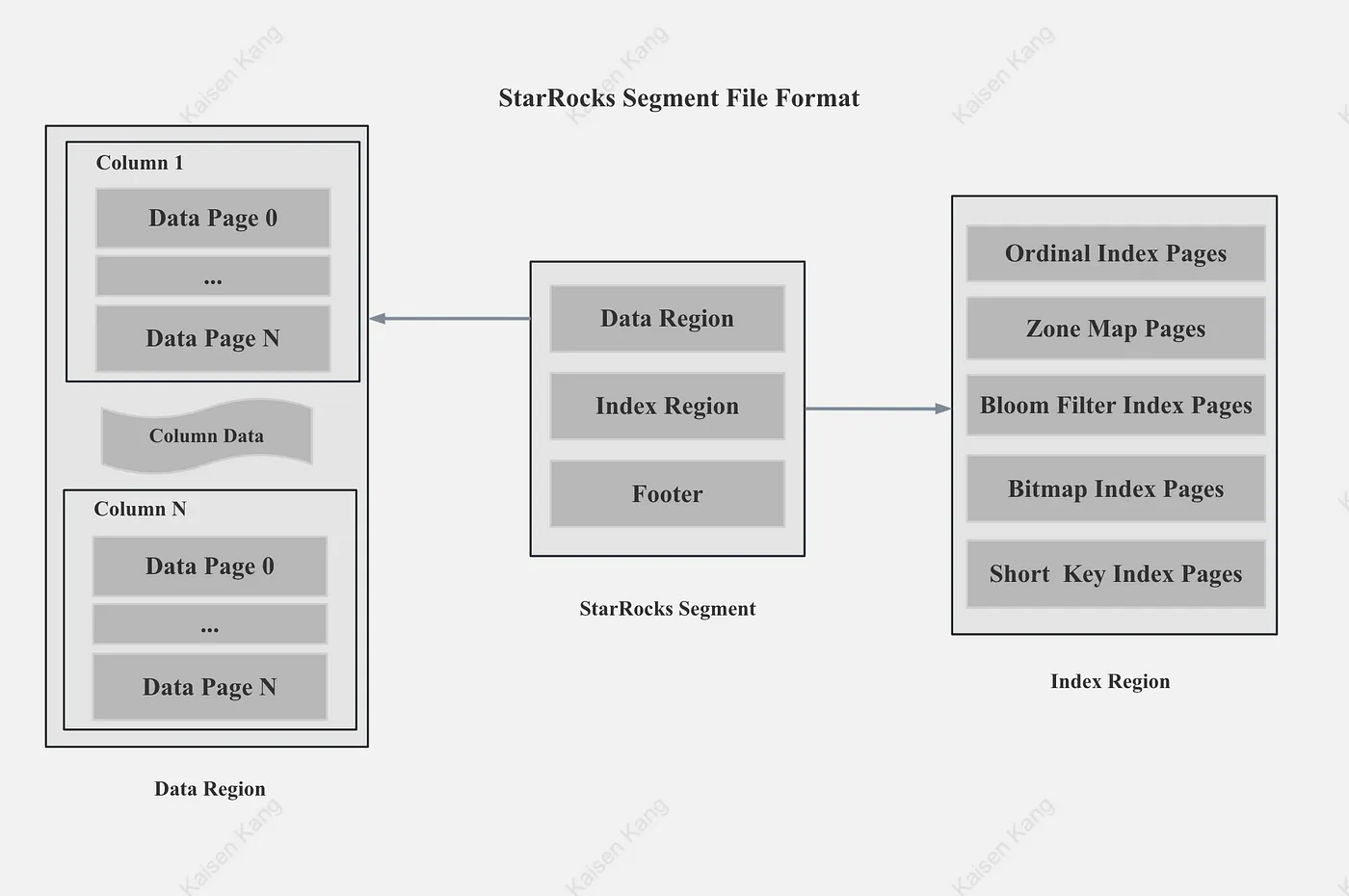
- 高效IO: 只读取必需的列
- 高效编码压缩:同一列的数据类型相同,数据特点相似,压缩比更高
- 丰富索引加速过滤
半结构化列存
索引
Hash 索引
B+ Tree 索引
Radix tree 索引
前缀索引
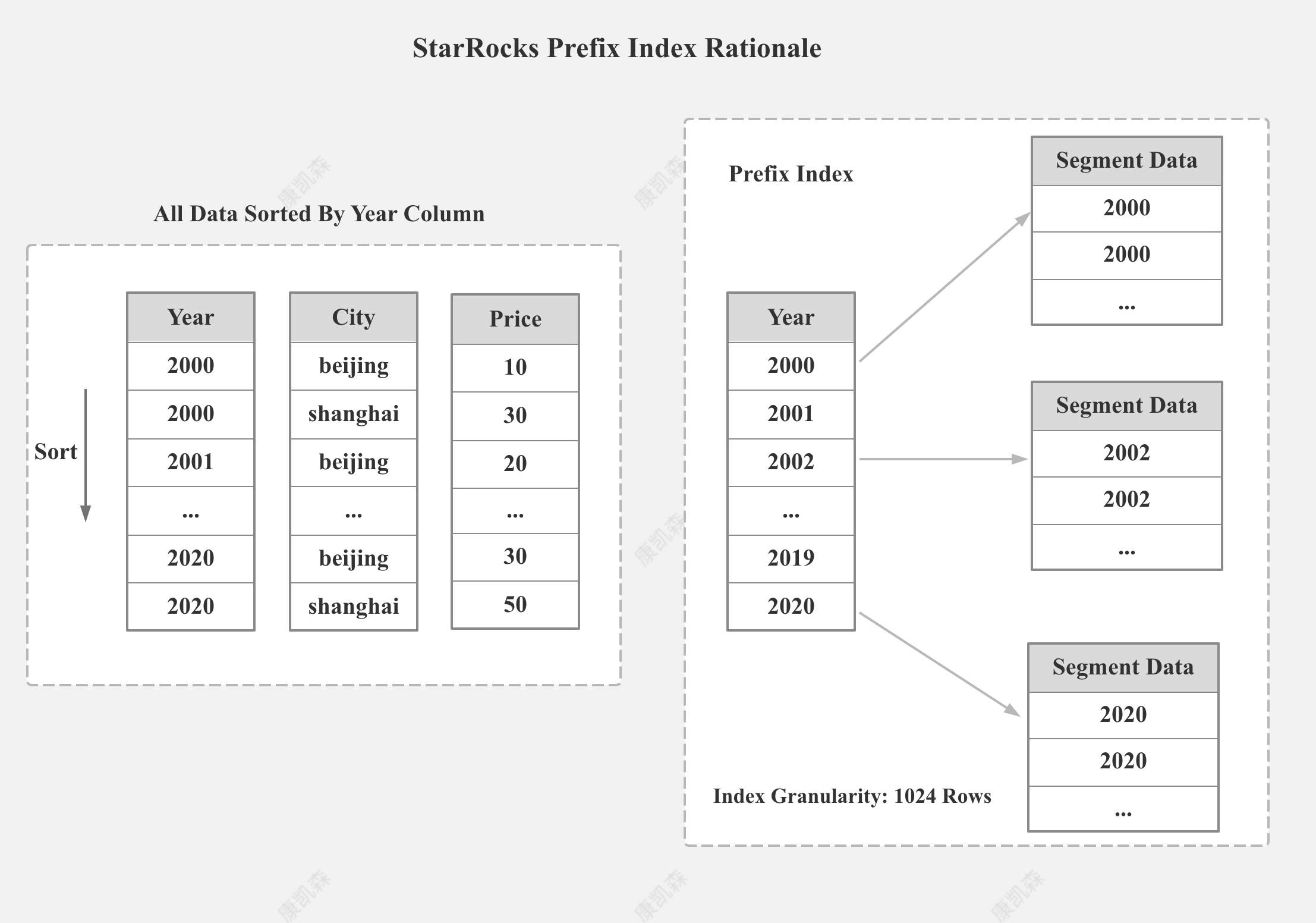
- 基于排序列
- 索引粒度:几千行
- 索引 Key: 一般有字节数的限制
ZoneMap 索引 (块索引)
块级索引,是以块为单位,记录块内元数据的索引(最大值、最小值、空值、COUTN、SUM、相关性等)
HyperLogLog 统计信息
Z-Order 索引
Liquid Clustering
Databricks Liquid Clustering 原理
BloomFilter 索引
过滤条件是 = 和 In
Bitmap 倒排索引
StarRocks Bitmap Index Rationale
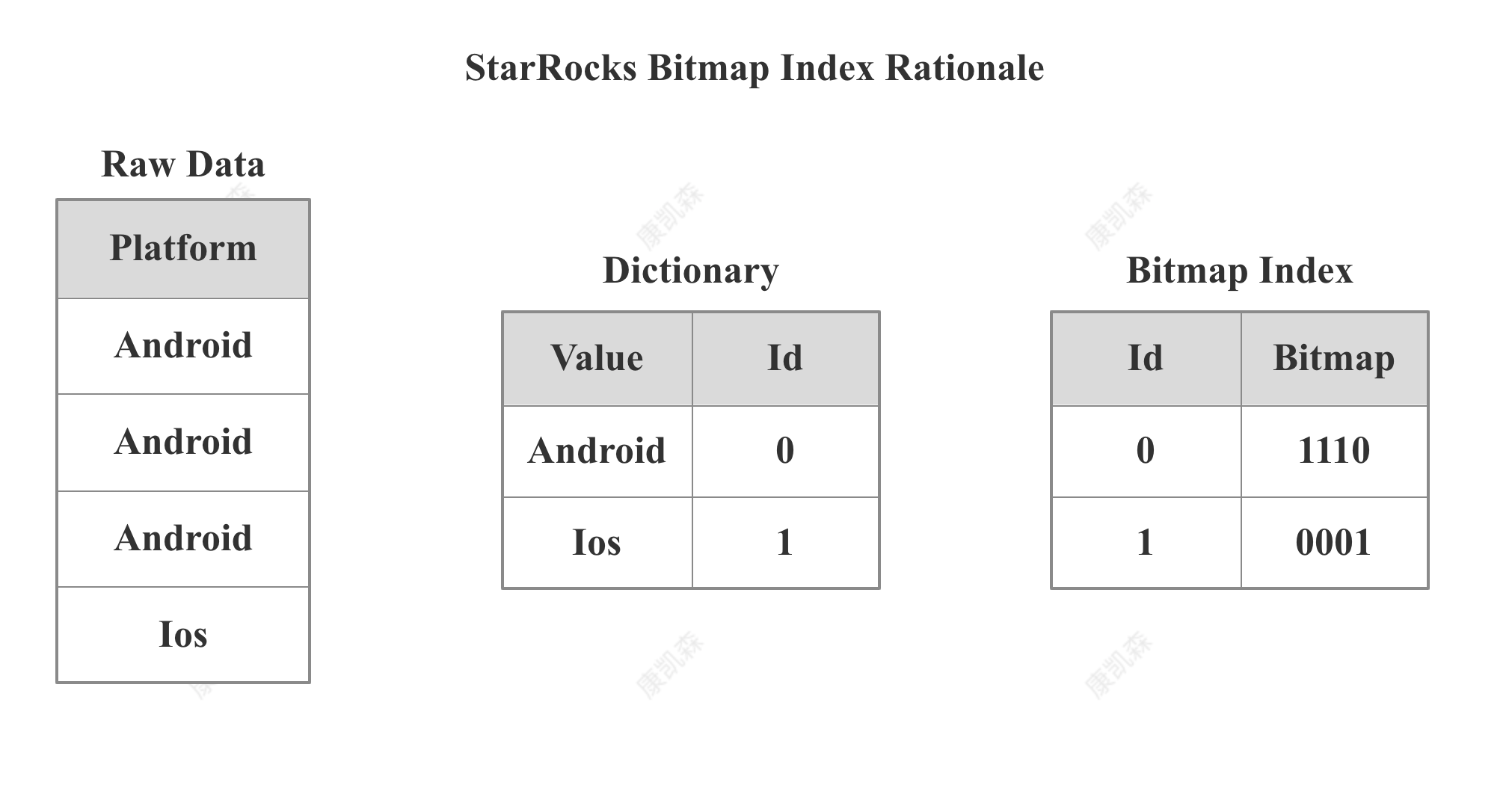
StarRocks 的 Bitmap Index 主要包括两部分内容:字典和 Bitmap 行号。 字典保存了原始值到编码 Id的映射,Bitmap 索引记录了每个编码 ID 到 Bitmap 行号的映射。
StarRocks Bitmap Index Storage Format
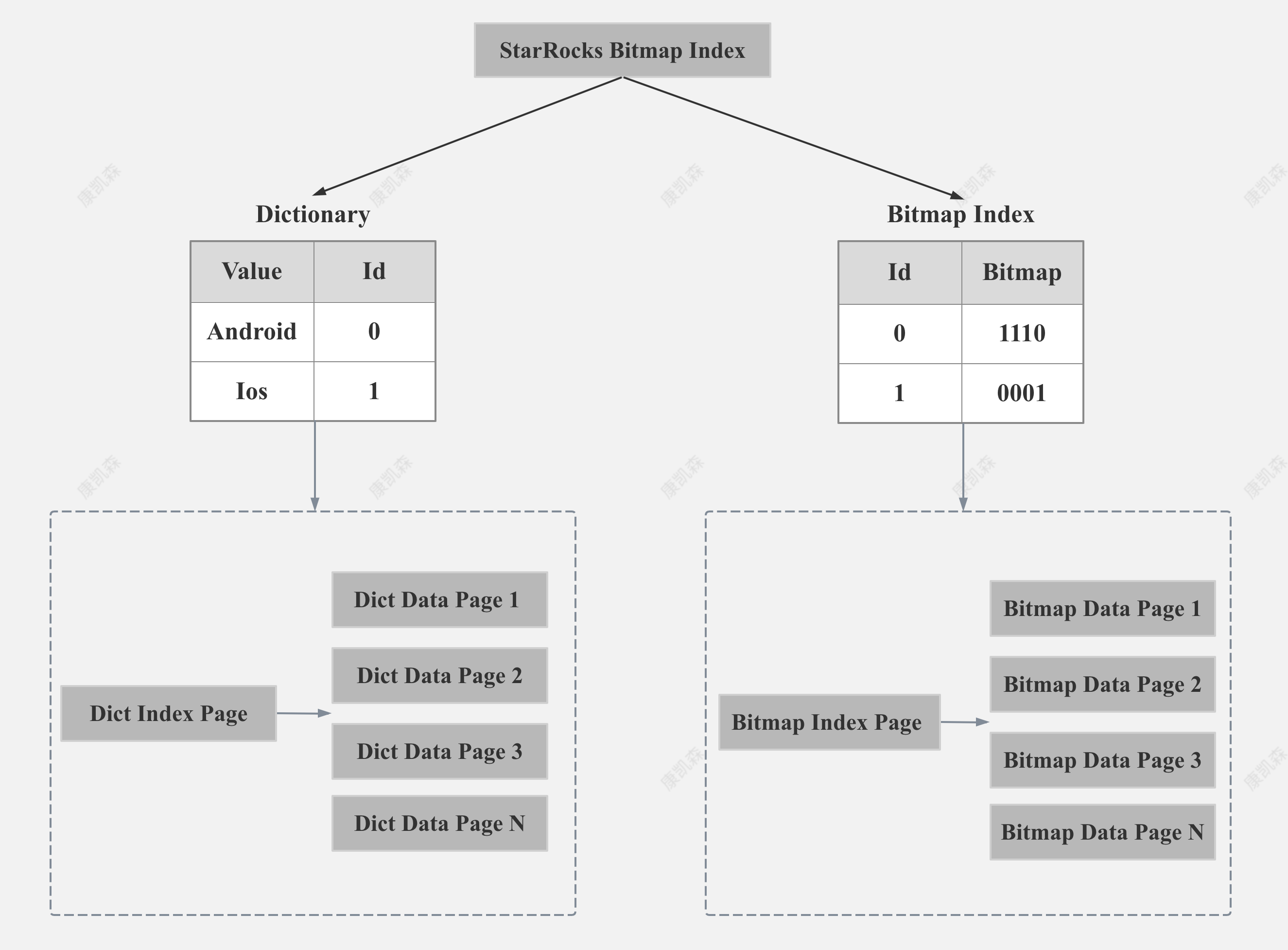
如上图所示,StarRocks 的字典部分和 Bitmap 行号部分都是以 Page 的格式存储,同时为了减少内存占用和加速索引,StarRocks 对字典和 Bitmap 的 Page 都建立了索引。
当然,如果建 Bitmap 索引列的基数很低,Dict Data Page 和 Bitmap Data Page 只有一个的话,我们就不需要 Dict Index Page 和 Bitmap Index Page。
Operation On Encode Data
当 StarRocks 利用 Bitmap Index 进行过滤的时候,只需要先加载 Dict Index Page 和部分 Dict Data Page 即可,按照字典值进行快速过滤,无需解码数据,也无需把所有 Bitmap Data Page 一次性加载进来。
综上,由于 StarRocks 支持Bitmap 索引的索引和支持按照字典值进行快速过滤,即使 Bitmap Index 列的基数很高,Bitmap Index 整体磁盘存储很大,内存占用也很小。
Bitmap 索引内存缓存
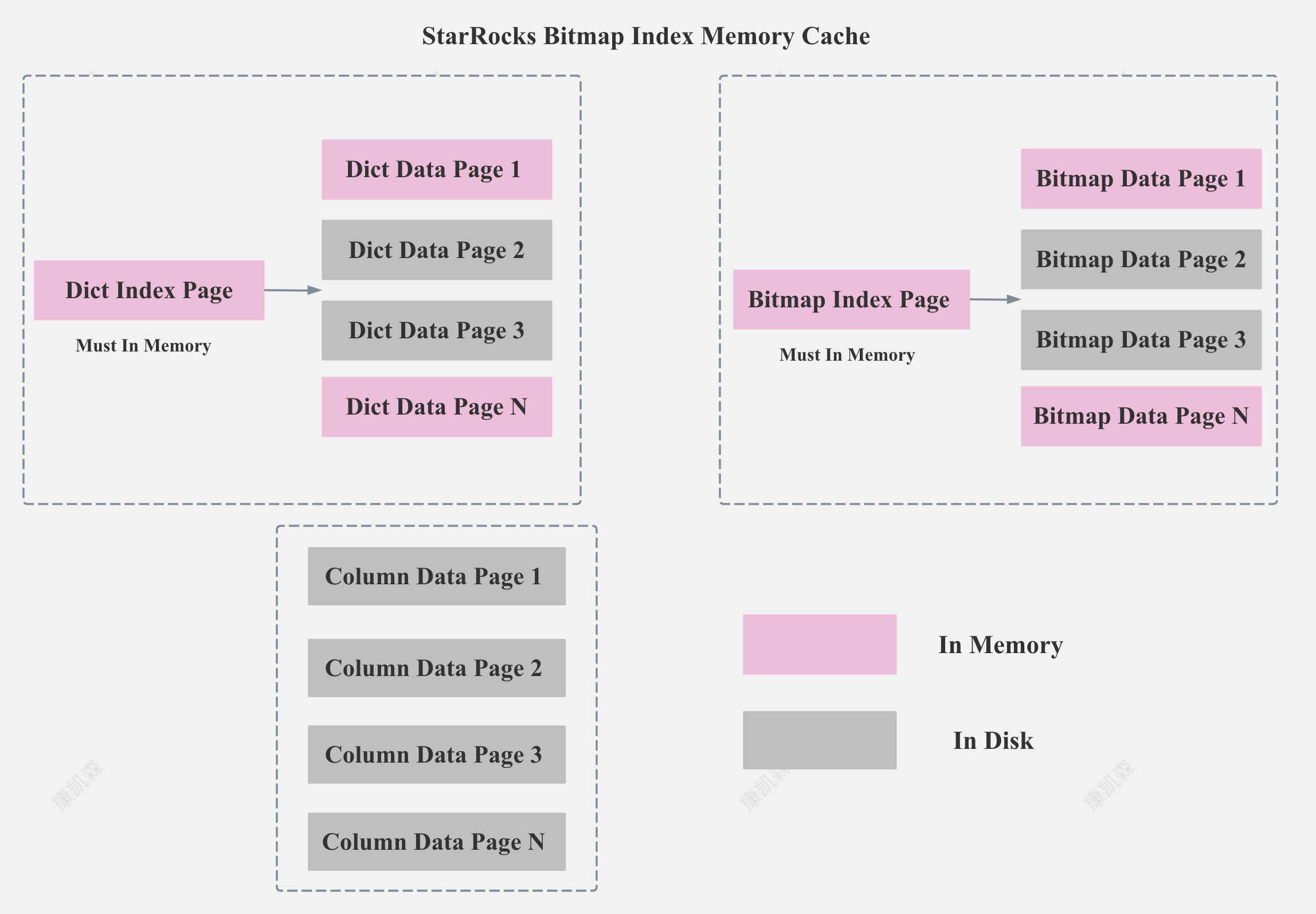
StarRocks 会保证所有的 Dict Index Page 和 Bitmap Index Page 一定在内存,并让尽可能多的 Dict Data Page 和 Bitmap Data Page 在内存,并保证 Bitmap Index 相关的 Page Cache 不被 Column 的数据冲掉。
这样在点查结果集较小的情况下,即使是第一次 Cold Query,StarRocks 也可以做到只需要一次 Disk Seek。
自适应 Bitmap 索引
当 StarRocks 发现 Bitmap 索引的选择度不高,需要 Seek 很多 Data Page 时,我们就会放弃使用 Bitmap 索引,直接顺序 Scan。
让索引常驻内存
物化列
Cache
多级 Cache
RaptorX: Building a 10X Faster Presto https://prestodb.io/blog/2021/02/04/raptorx
- Metastore Versioned Cache
- File List cache
- Fragment Result Cache
- File Descriptor and Footer Cache
- Alluxio Data Cache
写入绕过 Cache
TencentCLS: The Cloud Log Service with High Query Performances https://www.vldb.org/pvldb/vol15/p3472-yu.pdf
vm.dirty_background_ratio vm.dirty_expire_centisecs
IO 线程和计算线程解耦
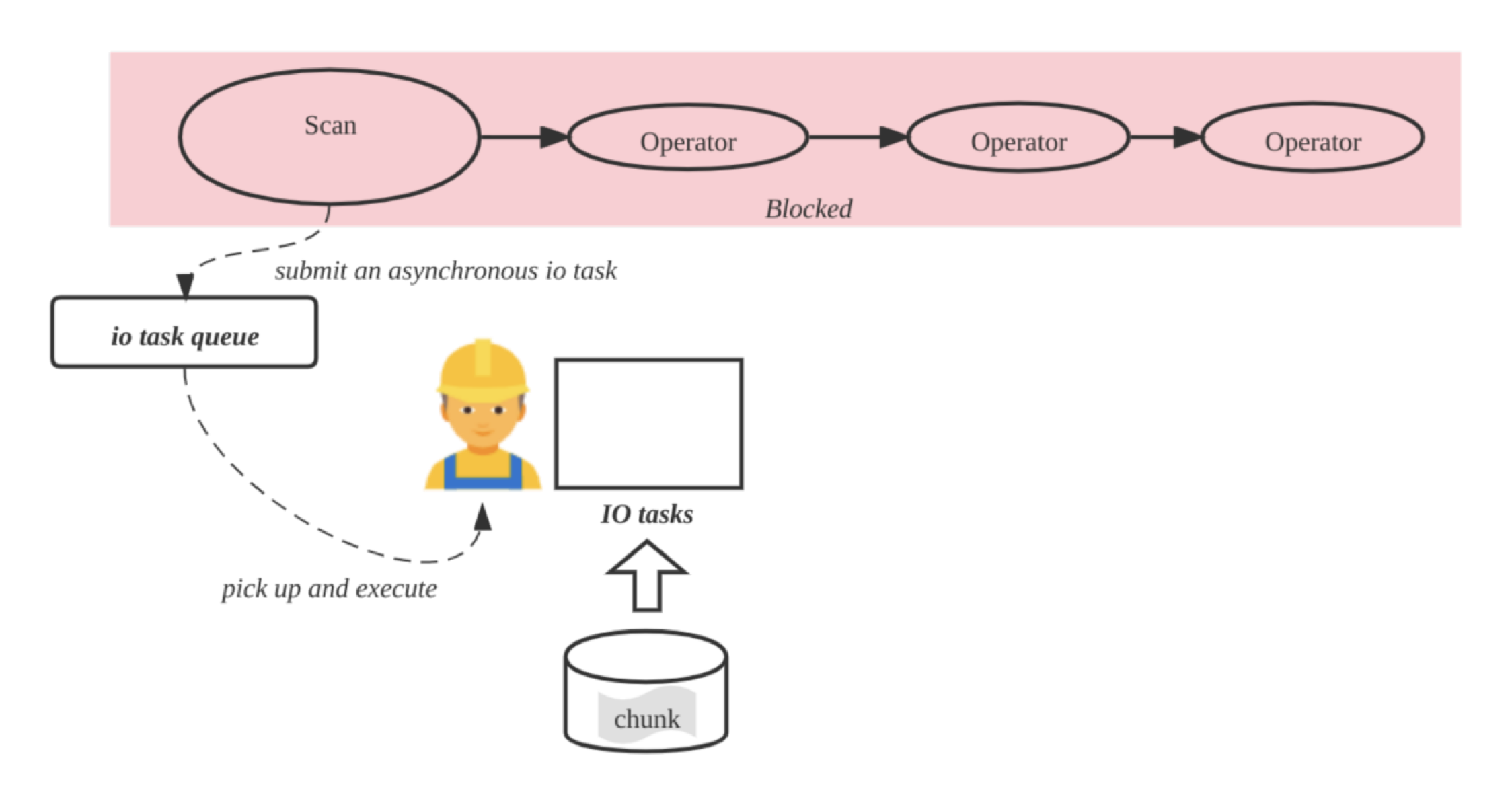
- Submit an asynchronous io tasks
- Fetch and cache chunk into chunk buffer
- Pull the chunk from the chunk buffer
异步 IO
IO异步化对于高性能的网络编程、服务器应用程序、多线程和多进程编程等场景非常有用,可以避免因IO阻塞而导致的资源浪费和性能瓶颈。它允许程序更加高效地利用计算资源,并提高系统的并发能力和响应性能。
IO 多路复用
IO 多路复用
IO 并行度 自适应
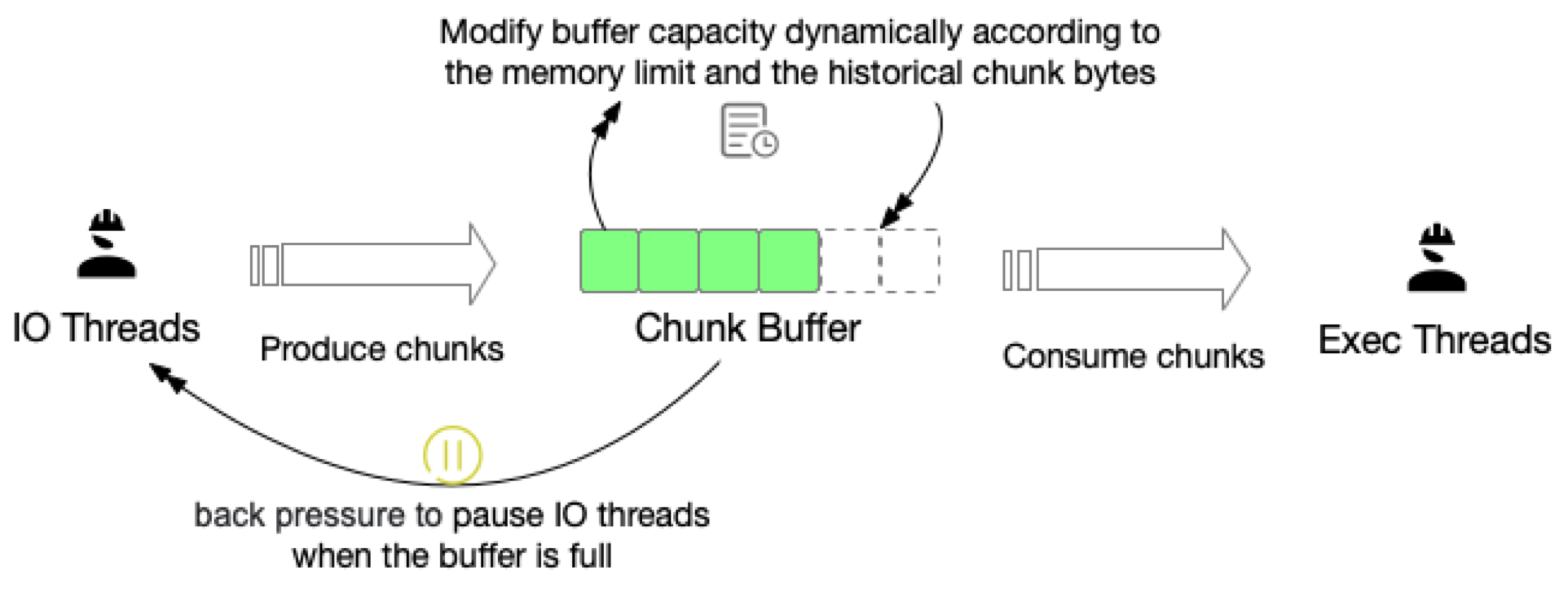
- Should control the memory usage of the Scan IO Tasks
- Adjust the IO concurrent by memory limit and heuristic chunk bytes
IO 调度
A New IO Scheduler Algorithm for Mixed Workloads
Scan 优先级
Shared Scan
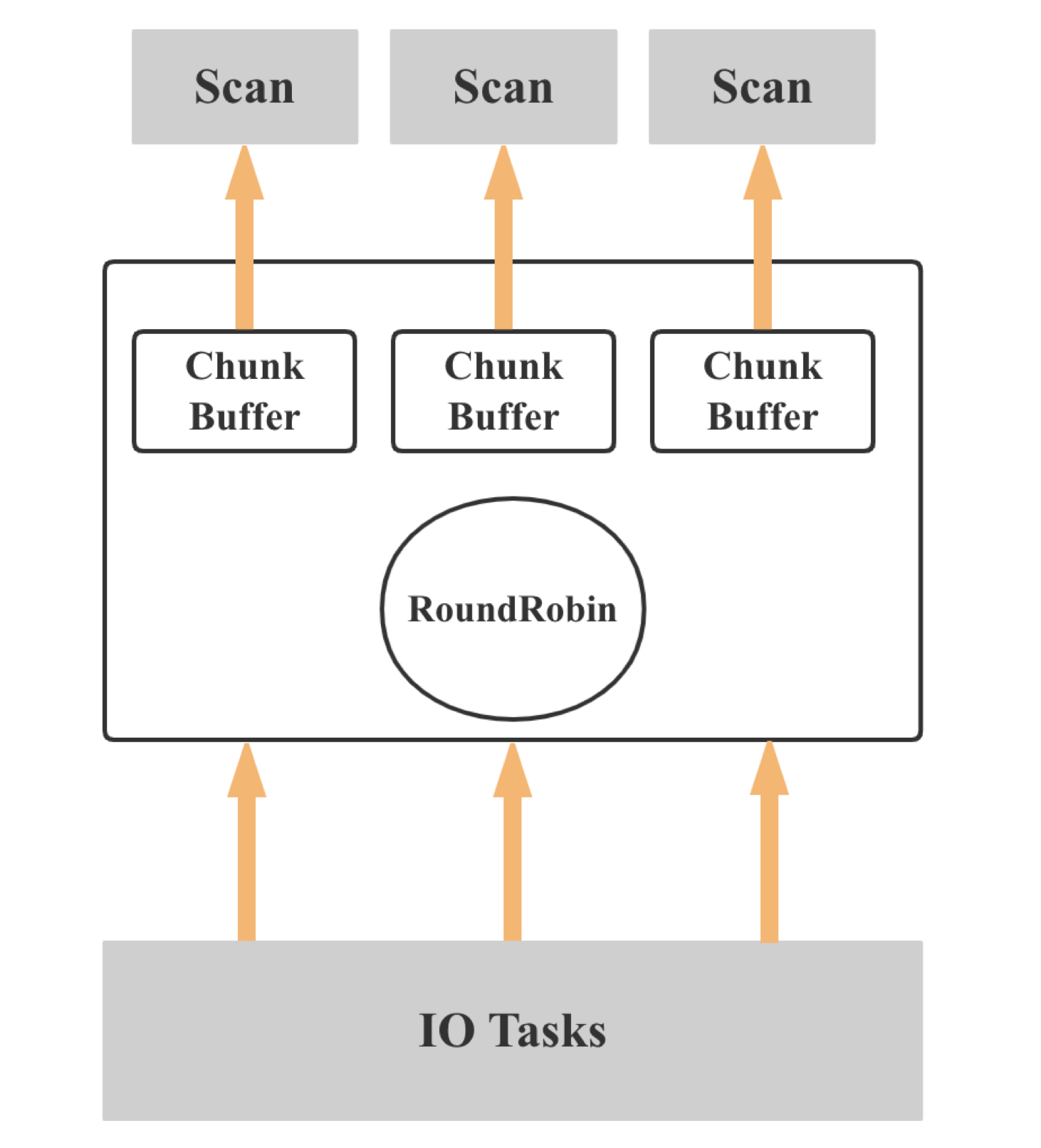
- Share the chunk buffer between scan operators
- Balance data among scan operators
- Resolve the natural tablet data skew
延迟物化
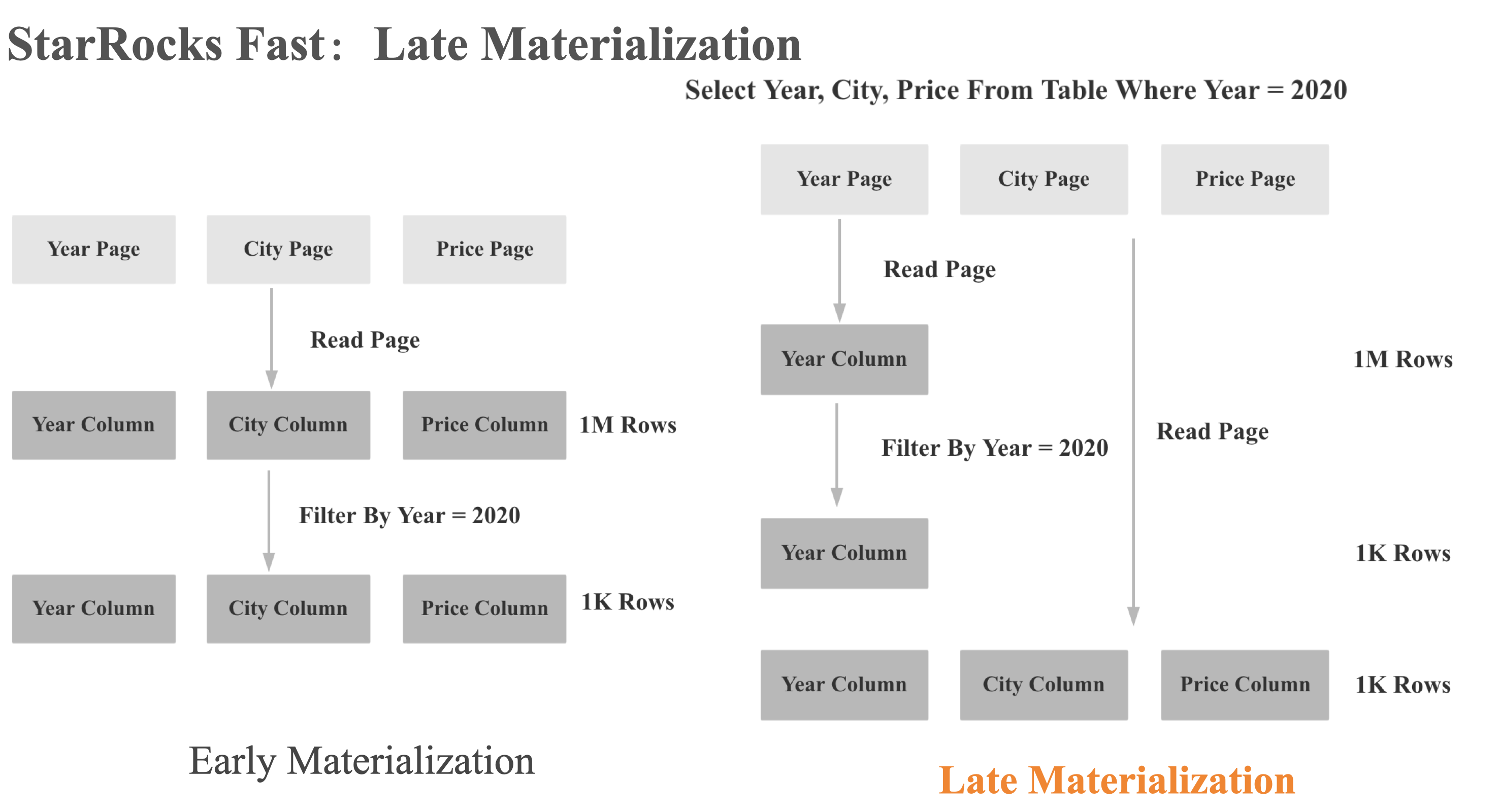
- 先只读取过滤条件中的列
- 再根据过滤后的行号读取其他的列
Segment 大小 / 文件大小
How Databricks improved query performance by up to 2.2x by automatically optimizing file sizes
文件的个数
太多的文件往往意味着太多的 IO 次数
文件的版本数
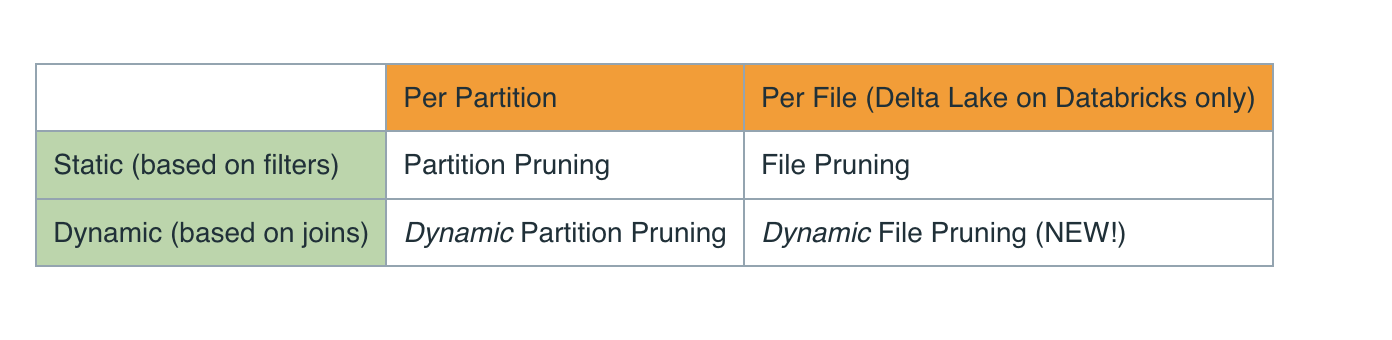
动态文件裁剪
数据局部性
压缩
Gzip
LZ4
Brotli
SNAPPY
ZSTD
BZIP2
编码
预取
Runtime filter
表达式下推存储层
Compaction

Compaction 如果不及时,会导致文件数过多,进而影响查询性能
Prefetch or Predictive Pipelining
根据访问模式,提前从存储层读取所需要的数据。
在存储分离的架构,合理地 Prefetch S3 等分布式存储的文件,对 Scan 性能的优化更明显
Announcing the General Availability of Predictive I/O for Reads
硬件
多块磁盘
在成本相差不大的情况下,多块磁盘可以获得更高 IOPS 和吞吐
NVMe
- Is Sequential IO Dead In The Era Of The NVMe Drive? https://jack-vanlightly.com/blog/2023/5/9/is-sequential-io-dead-in-the-era-of-the-nvme-drive